Code
library(tidyverse)
load("./data/zufallsdaten4A.RData")
zufallsdaten <- zufallsdaten |>
mutate(bernoullivar08 = if_else(univar13 <= 2.6, 1L, 0L))Es ist gar nicht so einfach, zufällige und nicht-zufällige Vorgänge voneinander zu unterscheiden. Wenn beispielsweise beim Würfeln dreimal hintereinander eine Eins erscheint, hat man intuitiv das Gefühl, beim nächsten Wurf müsse nun doch mit sehr hoher Wahrscheinlichkeit eine andere Augenzahl erscheinen. Stattdessen ist diese Wahrscheinlichkeit nach wie vor 5/6, denn der Würfel hat kein Gedächtnis und weiss nicht, dass bereits dreimal hintereinander die Eins erschienen ist; ob also beim nächsten Wurf eine von Eins verschiedene Zahl erscheint, hängt nicht davon ab, wie oft davor eine Eins geworfen wurde.
In dieser Aufgabe können Sie Ihre Intuition den Zufall betreffend unter Beweis stellen.
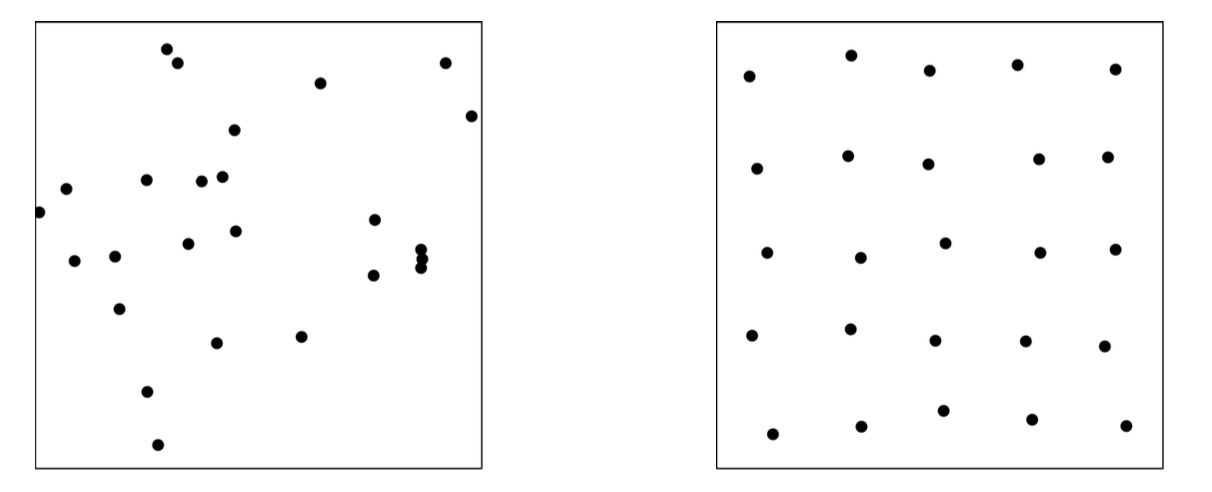
In einem der beiden folgenden Quadrate sind die Punkte eher gleichförmig zufällig verteilt als im andern, d.h. jedes gleich grosse Flächenstück hat dieselbe Wahrscheinlichkeit, 1, 2, 3, …, Punkte zu enthalten, egal wo im Quadrat es sich befindet (genauer gesagt: die \(x\)- und die \(y\)-Koordinaten der Punkte im Quadrat sind jeweils stetig gleichverteilt). In welchem Quadrat sind also die Punkte eher gleichförmig zufällig verteilt, und in welchem eher nicht?
In einer der folgenden beiden Zahlenfolgen wurde für jedes Folgenglied jeweils zufällig mit gleicher Wahrscheinlichkeit eine Zahl aus der Menge \(\{1, 2, 3, 4\}\) ausgewählt (diskrete Gleichverteilung), und bei der andern Zahlenfolge nicht. Bei welcher Folge wurden die Glieder eher zufällig gleichverteilt ausgewählt?
Folge 1: 4, 2, 2, 3, 1, 3, 1, 1, 2, 4, 2, 1, 3, 1, 3, 4, 3, 1, 3, 4, 1, 3, 3, 3, 3, 4, 2, 1, 3, 1, 3, 2, 2, 3, 1, 3, 4, 4, 2
Folge 2: 4, 3, 1, 2, 1, 3, 4, 2, 3, 4, 2, 1, 3, 1, 2, 4, 4, 2, 1, 3, 1, 4, 4, 3, 1, 4, 2, 4, 1, 1, 2, 3, 2, 4, 1, 1, 3, 1, 3, 2, 4, 1, 1, 4, 2, 3
a) Das linke Diagramm zeigt eher gleichförmig zufällig verteilte Punkte. Vorsicht: Gleichförmig zufällig verteilt heisst nicht regelmässig verteilt! Grosse Regelmässigkeit ohne Häufungen deutet also eher darauf hin, dass eine Verteilung nicht gleichförmig zufällig (ja vielleicht nicht einmal zufällig!) ist.
b) Die Folge 1 enthält eher zufällig gleichverteilt ausgewählte Zahlen. In Folge 2 kommen beispielsweise nie zweimal hintereinander dieselben Zahlen vor, was bei einer Zufallsfolge dieser Länge und mit diesem kleinen Wertebereich sehr unwahrscheinlich ist. Auch hier gilt: Grosse Regelmässigkeit bzw. die Abwesenheit von Häufungen deutet eher darauf hin, dass keine Gleichverteilung (und vielleicht sogar überhaupt keine rein zufällige Verteilung) vorliegt.
In einem RAID-5-System (RAID = “redundant array of independent disks”) mit 4 identischen Festplatten werden die Daten zusammen mit zusätzlichen Informationen (Paritätsinformationen) so gespeichert, dass beim Ausfall einer Festplatte aus den andern 3 Festplatten sämtliche Daten wieder rekonstruiert werden können. Dabei steht insgesamt über alle 4 Festplatten der Speicherplatz von 3 Festplatten für Daten zur Verfügung.
Angenommen, man geht davon aus, dass jede einzelne Festplatte mit derselben Wahrscheinlichkeit von \(p = 0.001\) innerhalb eines bestimmten Zeitraums ausfällt.
Wie gross ist die Wahrscheinlichkeit, dass innerhalb dieses Zeitraums
Festplatte(n) ausfällt/ausfallen?
Wie gross ist der Erwartungswert und die Varianz der Anzahl ausfallender Festplatten in diesem Zeitraum?
Die Anzahl ausgefallener Festplatten im angegebenen Zeitraum ist eine binomialverteilte Zufallsvariable \(X\) mit \(n = 4\) Versuchen und “Erfolgswahrscheinlichkeit” (Ausfallwahrscheinlichkeit) \(p = 0.001\).
a) Für die gesuchte Wahrscheinlichkeit gilt bei dieser binomialverteilten Zufallsvariablen \(X\):
\[P(X = k) = \binom{n}{k} p^k (1-p)^{n-k} = \binom{4}{k} 0.001^k (1-0.001)^{4-k}\]
Somit ist
\[P(X = 0) = \binom{4}{0} 0.001^0 \cdot 0.999^4 \approx 0.996\]
\[P(X = 1) = \binom{4}{1} 0.001^1 \cdot 0.999^3 \approx 0.003988\]
\[P(X = 2) = \binom{4}{2} 0.001^2 \cdot 0.999^2 \approx 5.988 \cdot 10^{-6}\]
b) Der Erwartungswert und die Varianz der Anzahl ausfallender Festplatten \(X\) im gegebenen Zeitraum ergeben sich als
\[E(X) = n \cdot p = 4 \cdot 0.001 = 0.004\]
\[\text{Var}(X) = n \cdot p \cdot (1-p) = 4 \cdot 0.001 \cdot 0.999 = 0.003996\]
Ob etwas zufällig ist oder nicht, lässt sich oft nur schwer erkennen. Umgekehrt haben wir meist grosse Mühe, z.B. selbst Zufallszahlen zu erzeugen. Wie erzeugt denn eigentlich R Zufallszahlen mit unterschiedlichen Verteilungen? Das Paradoxe ist, dass R (und die vielen andern, existierenden Statistikprogramme) zufällige Zahlen nach bestimmten Algorithmen berechnen – obwohl sich berechnet und zufällig doch eigentlich gegenseitig ausschliessen! Wenn eine Zahl berechnet wird, kann sie nicht wirklich zufällig sein. Statistikprogramme erzeugen mit Hilfe spezieller Funktionen, Zufallszahlen-Generatoren genannt, auch tatsächlich nicht wirkliche Zufallszahlen sondern sogenannte Pseudo-Zufallszahlen, also Zahlen, welche zwar nicht zufällig sind, sich aber von wirklichen Zufallszahlen kaum unterscheiden lassen. Das hat sogar Vorteile, z.B. für die Reproduzierbarkeit: Man kann einen solchen Zufallszahlen-Generator so initialisieren, dass er anschliessend jedesmal dieselbe Folge von Pseudo-Zufallszahlen liefert (in R geschieht das über die Funktion set.seed()).
Für diskrete oder stetige Zufallszahlen (genauer: diskrete oder stetige Zufallsvariablen) gibt es eine Unmenge an möglichen Wahrscheinlichkeitsverteilungen, von denen in diesem Modul nur die wichtigsten behandelt werden können. Wie erzeugt ein Statistikprogramm Pseudo-Zufallszahlen mit einer bestimmten Verteilung? Zuerst werden immer stetig-gleichverteilte Pseudo-Zufallszahlen erzeugt. Alle Pseudo-Zufallszahlen mit einer andern Verteilung werden dann aus solchen gleichverteilten Pseudo-Zufallszahlen mit Hilfe von geeigneten Umformungen berechnet. Berechnungen dieser Art führen Sie in der folgenden Aufgabe selbst durch.
Die Variable univar13 in der beiliegenden Datei zufallsdaten4A.RData (auf Moodle Block 4, Vorbereitung) enthält stetig-gleichverteilte Zufallszahlen im Intervall \([1, 3]\).
Erzeugen Sie aus univar13 eine Variable bernoullivar08, die Zufallszahlen mit einer Bernoulli-Verteilung – d.h. mit einer diskreten Verteilung! – enthält, wobei die Erfolgswahrscheinlichkeit \(p = 0.8\) sein soll. Weisen Sie auf geeignete Art und Weise nach, dass diese Variable auch tatsächlich Zufallszahlen der gewünschten Verteilung enthält.
Schildern Sie, wie Sie aus bernoullivar08 eine neue Variable binomialvar mit binomialverteilten Zufallszahlen erzeugen könnten. Dabei soll \(p = 0.8\) gelten, und der Erwartungswert der Binomialverteilung soll gleich 4 sein.
Die Berechnung selbst brauchen Sie in R nicht durchzuführen.
a) Die Zufallszahlen können über das Menü Datenmanagement | Variablen bearbeiten | Rekodiere Variablen … und beispielsweise folgende Rekodierungsanweisung erzeugt werden:
library(tidyverse)
load("./data/zufallsdaten4A.RData")
zufallsdaten <- zufallsdaten |>
mutate(bernoullivar08 = if_else(univar13 <= 2.6, 1L, 0L))Der Nachweis erfolgt z.B. mit einer Häufigkeitstabelle. Dabei sind natürlich (nicht allzu grosse) Abweichungen von den erwarteten relativen Häufigkeiten völlig normal. Je grösser die Anzahl Beobachtungen ist, desto näher sollte die empirische Verteilungsfunktion der erzeugten Zufallszahlen bei der vorgegebenen Verteilung liegen.
Hier folgt die Häufigkeitstabelle aus R, wenn die oben stehende Rechnungsanweisung verwendet wird:
zufallsdaten |>
count(bernoullivar08) |>
mutate(prozent = round(100 * n / sum(n), 2)) bernoullivar08 n prozent
1 0 195 19.5
2 1 805 80.5b) Für die gesuchte Binomialverteilung mit \(n\) Versuchen und der Erfolgswahrscheinlichkeit \(p = 0.8\) muss hier für den Erwartungswert gelten \(n \cdot p = n \cdot 0.8 = 4\); also ist \(n = 4/0.8 = 5\). Es liessen sich also aus den 1000 Beobachtungen von bernoullivar08 insgesamt 200 Beobachtungen mit der gewünschten Binomialverteilung realisieren, wenn z.B. jeweils 5 aufeinander folgende Werte von bernoullivar08 addiert würden. Das ist in R zwar machbar, gehört aber eher zu den fortgeschrittenen Themen und wird im Begleitkurs für R nicht behandelt. Eine Alternative bestünde darin, in einem Datensatz 5 Variablen mit jeweils bernoulliverteilten Zufallszahlen mit \(p = 0.8\) zu erzeugen und daraus die gesuchte Variable mit den binomialverteilten Zufallszahlen als Summe über diese 5 Variablen zu konstruieren (Summieren ist einfacher über Variablen als über Beobachtungen).